Why Graphiti
I’ve written GraphQL and had a pleasant experience. I have enormous respect for GraphQL. I also believe there is a fundamental flaw in GraphQL’s design.
Let’s remember why people like GraphQL in the first place - because it addressed common frustrations with REST APIs:
[We] heard from integrators that our REST API also wasn’t very flexible. It sometimes required two or three separate calls to assemble a complete view of a resource. It seemed like our responses simultaneously sent too much data and didn’t include data that consumers needed.
- “The Github Graph API”, GitHub Engineering
GraphQL solves real problems. Its flaw is that it solved these problems using zero-sum thinking: we must abandon the existing paradigm and forge a new one. It’s GraphQL versus REST, one or the other. REST is dead, long live GraphQL.
Graphiti instead approaches the problem using positive-sum thinking:
Positive-sum thinking is how we embrace pluralism while retaining a coherent vision and set of values…A zero-sum view would assume that apparent oppositions are fundamental, e.g., that appealing to the JS crowd inherently hurts the C++ one. A positive-sum view starts by seeing different perspectives and priorities as legitimate and worthwhile, with a faith that by respecting each other in this way, we can find strictly better solutions than had we optimized solely for one perspective.
- “Listening and Trust”, Aaron Turon
GraphQL optimized around REST’s shortcomings, and in doing so it dropped REST’s advantages. There is no need for such a zero-sum tradeoff. We can take everything great about GraphQL and build it on top of REST (and HTTP!), instead of replacing it altogether. We can have our cake and eat it too.
REST

You’ll find plenty of GraphQL posts that describe REST as an inflexible paradigm of a bygone era, a lack of granularity that necessarily leads to data under- and over-fetching.
It’s true that many REST APIs work this way, but this is not REST. While there’s endless debate around which APIs are considered “RESTful”, I don’t think we need to look much further than what the letters actually stand for:
Representational State Transfer. This sentence is not only what REST stands for, it is also the tiniest possible description of what REST actually means…It is not a standard, rather a style describing the act of transfering a state of something by its representation.
Let’s consider this:
Marcus is a farmer. He has a ranch with 4 pigs, 12 chickens and 3 cows. He is now simulating a REST API while I am the client. If I want to request the current state of his farm using REST I just ask him: “State?”
Marcus answers: “4 pigs, 12 chickens, 3 cows”. This is the most simple example of Representional State Transfer. Marcus transfered the state of his farm to me using a representation. The representation of the farm is the plain sentence: “4 pigs, 12 chickens, 3 cows”.
So lets get to the next level. How would I tell Marcus to add 2 cows to his farm the REST way? Maybe tell him: “Marcus, please add 2 cows to your farm”.
Do you think this was REST? Are we transfering state by its representation here? NO! This was calling a remote procedure. The procedure of adding 2 cows to the farm.
Marcus sadly answers: “400, Bad Request. What do you mean?”
So lets try this again. How would we do this the REST way? What was the representation again? It was “4 pigs, 12 chickens, 3 cows”. Ok. so let’s try this again transfering the representation…
me: “Marcus, … 4 pigs, 12 chickens, 5 cows … please!”. Marcus: “Alright !”. me: “Marcus, … what is your state now?”. Marcus: “4 pigs, 12 chickens, 5 cows”. me: “Ahh, great!” See? It was really not that hard and it was REST.
- “Why REST Is So Important”, Gregor Riegler
In other words, this is REST:

We’re moving an object from the server to the client, possibly modifying that object, then moving back to the server.
The other important aspect of REST is Links. Because all objects are addressable at a URL, we can use HTTP links to connect Resources. This allows for (among other things) lazy-loading - the logic connecting Resources can be changed server-side without breaking clients. If we have a “Top Comments” relationship, we can redefine “Top” without disturbing clients.
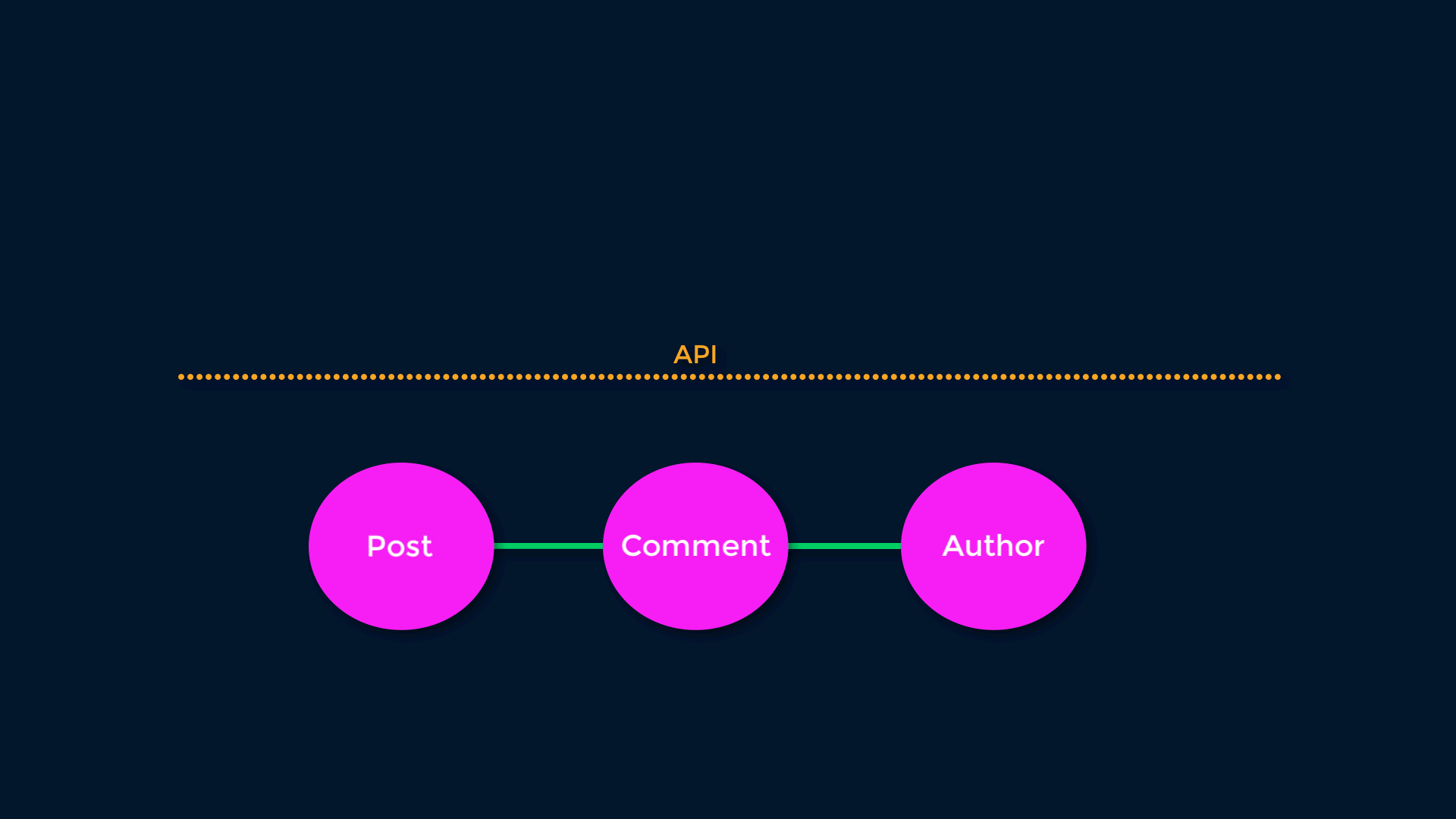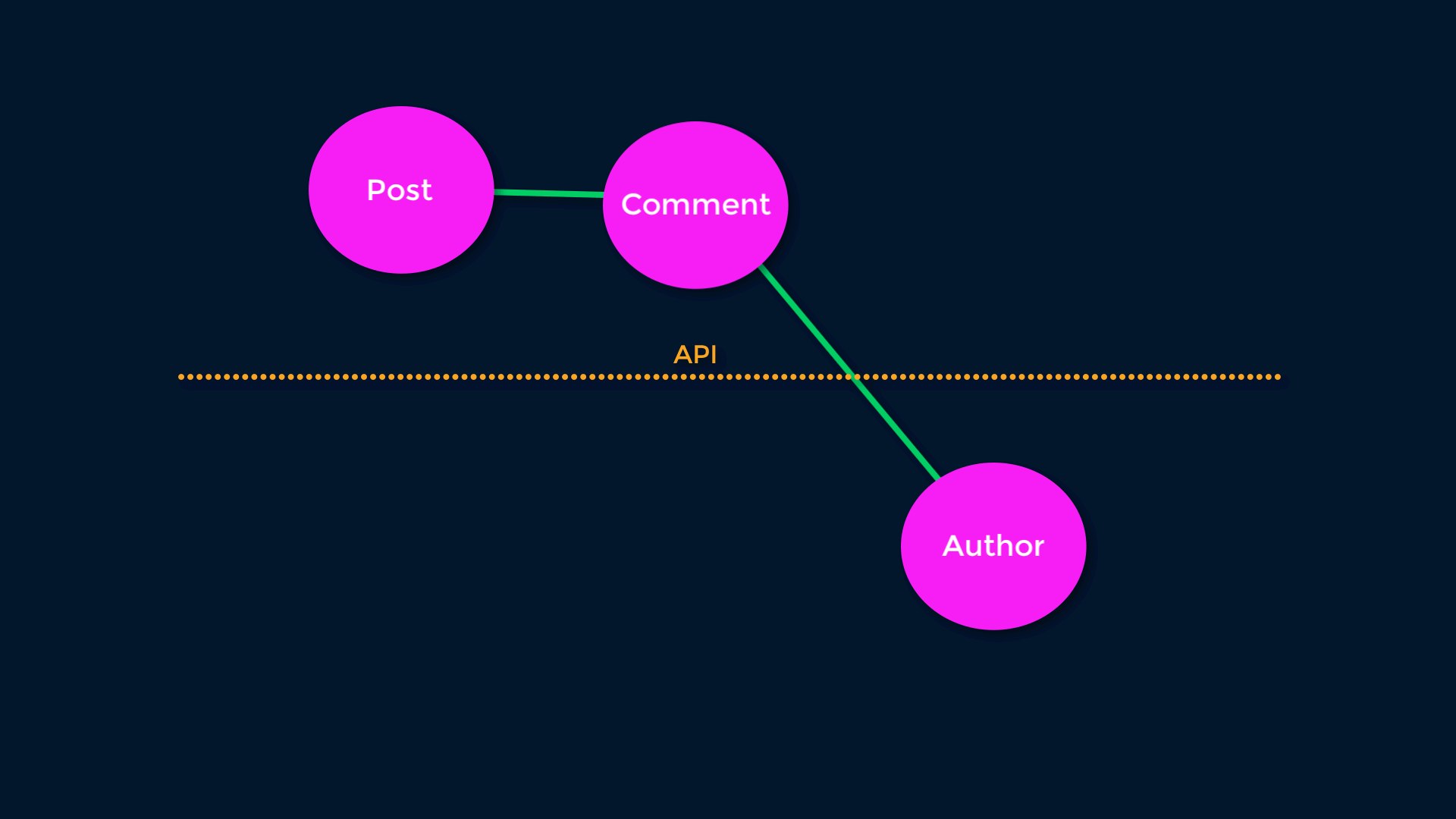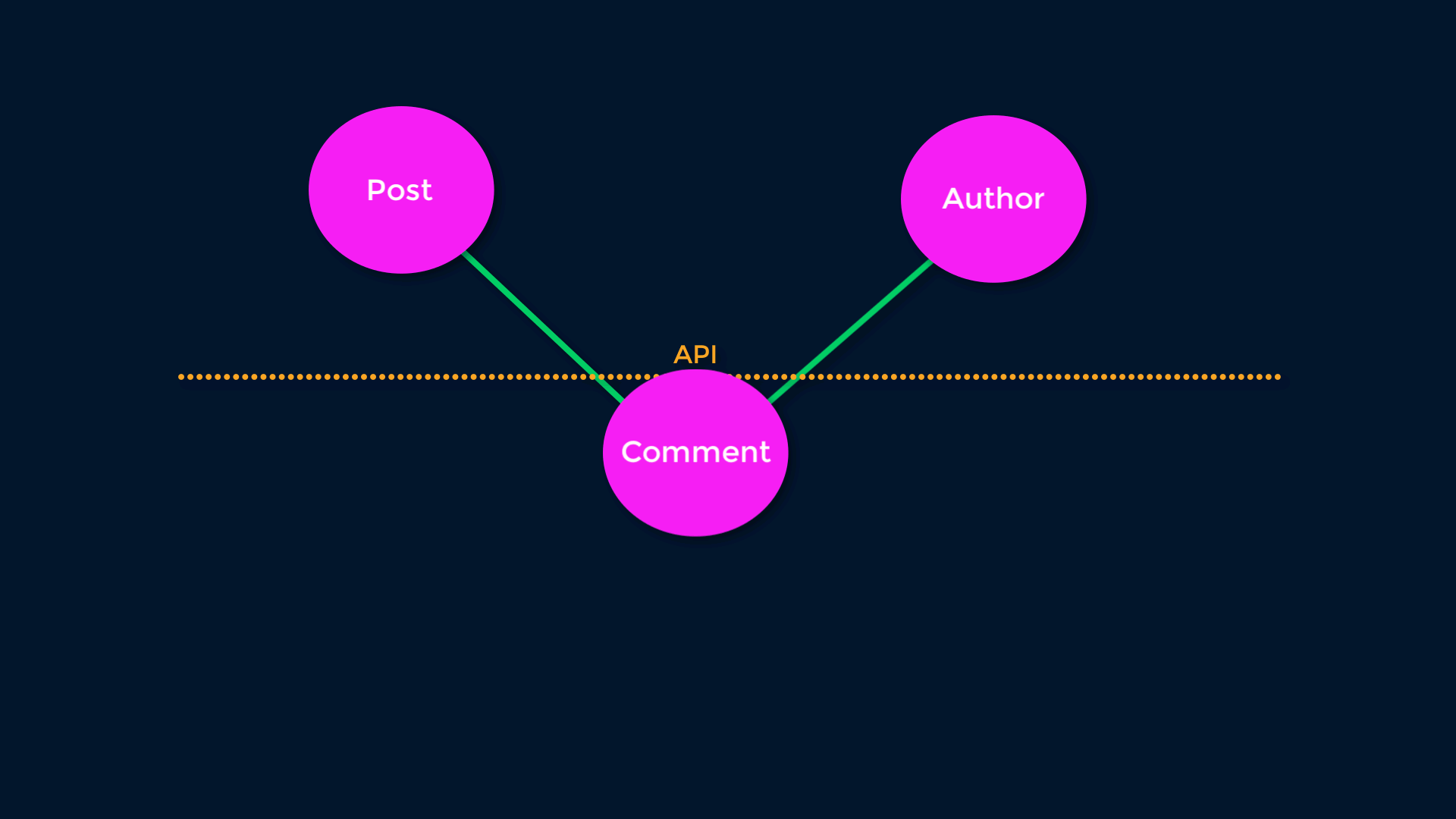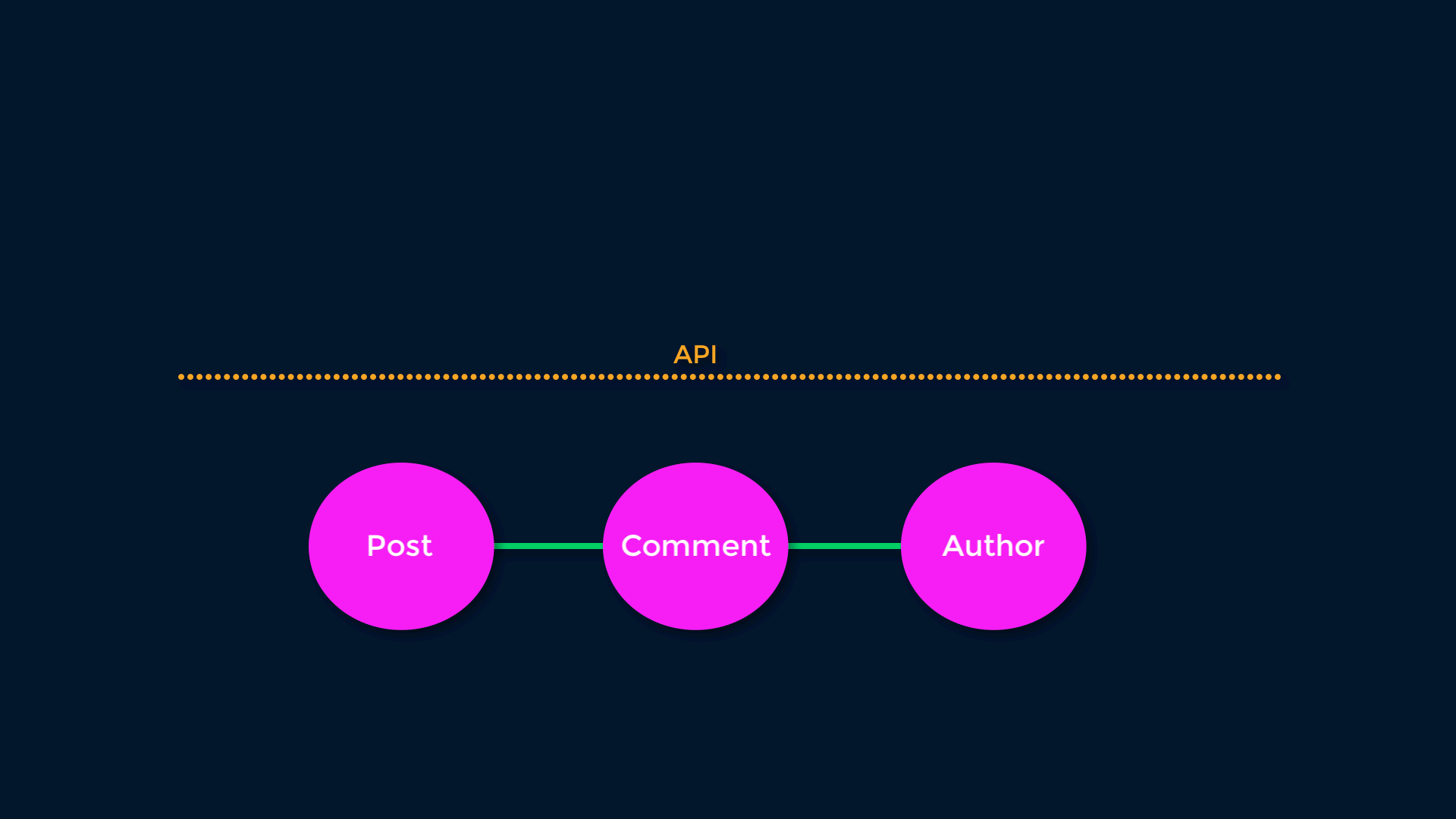
Pretty simple right? Here’s how we might implement this in GraphQL:
type CreateEmployeeInput {
name: String
age: Int
}
type CreateEmployeePayload {
employee: Employee
}
type UpdateEmployeeInput {
employeeId: ID!
name: String
age: Int
}
type UpdateEmployeePayload {
employee: Employee
}
type DestroyEmployeeInput {
id: ID!
}
type DestroyEmployeePayload {
employee: Employee
}
type Employee {
id: ID!
name: String
}
createEmployee(input: CreateEmployeeInput!): CreateEmployeePayload
updateEmployee(input: UpdateEmployeeInput!): UpdateEmployeePayload
destroyEmployee(input: DestroyEmployeeInput!): DestroyEmployeePayload
employee(id: ID!): EmployeeThe first thing to note is that GraphQL is super badass at describing fields and types. The next thing to note is that fields and types are the wrong abstraction.
Defining a schema like this allows bespoke, fine-grained detail. If we
wanted, the CreateEmployeePayload could be different than the
UpdateEmployeePayload - same for inputs like CreateEmployeeInput and
UpdateEmployeeInput. If we wanted other actions, like
promoteEmployee or deactivateEmployee, they would be easy to add and
follow the same basic constructs.
This is RPC - hand-crafted, custom requests. We have a high level of
configuration but a low level of convention. Not only will
developers have to spend more time hand-crafting these requests, but
patterns are likely to diverge from one API to the next, from team to
team, as time moves on. In fact, the above is really a best-case
scenario with common naming convention of create/update/destroy - the
Github API adds verbs like add, remove, lock, move and more.
Oh, and we dropped support for lazy-loading along the way.
Conventions

The benefit of REST over RPC is conventions. Conventions cause increased productivity and consistency (leading to fewer misunderstandiings and chances for bugs). Let’s start thinking in REST, and see where it takes us.
In REST, we know the input and output is always the Resource:
type Employee {
id: ID!
name: string
}
createEmployee(input: Employee): Employee
updateEmployee(input: Employee!): Employee
destroyEmployee(input: Employee!): Employee
employee(id: ID): EmployeeOK, a little tighter. But there’s actually no reason to type this out each time - we can assume developers are already familiar with the convention.
type Employee {
id: ID!
name: string
}
createEmployee
updateEmployee
destroyEmployee
employee(id: ID)Getting there. OK, and we know we’re dealing with an Employee, and we
know we won’t have custom verbs like promote or remove - we’re
moving objects here, and nothing else (if that throws you for a mental
loop, see this presentation by Derek Prior, Engineering Manager at
GitHub).
type Employee {
id: ID!
name: string
}
create
update
destroy
show // employee(id: ID)
index // employee()By adopting conventions, we not only removed boilerplate - we removed the chance of subtle inconsistencies. This is better for both providers and consumers of the API.
We’re just getting started.
The above schema covers basic CRUD. But we probably want to filter data, right? Let’s say we want to return all employees with a given name:
employee(id: ID, name: String)Again, we’re seeing chances for inconsistency. What’s the name
parameter - straight equality? Case sensitive? Contains? I guess we
could throw a bunch of suffixes at it:
employee(id: ID, name_eq: String, name_suffix: String, name_prefix: String, name_contains: String, name_not_eq: String, name_not_suffix: String, name_prefix: String, name_not_prefix: String)Works, but a bit unwieldy…and again, likely to diverge wildly across implementations.
What about sorting? Should we do it similar to the Github API?:
enum OrderDirection {
ASC
DESC
}
enum EmployeeOrderField {
ID
NAME
}
type EmployeeOrder {
field: EmployeeOrderField!
direction: OrderDirection
}
employee(orderBy: EmployeeOrder)Or should we do it like How to GraphQL?:
enum EmployeeOrderByInput {
id_ASC
id_DESC
name_ASC
name_DESC
}
employee(orderBy: EmployeeOrderByInput)We have divergent APIs right off the bat, and neither one supports multisort.
Rethinking REST

Earlier, we covered RESTfully moving an object between the server and the client. Those objects connected together with Links, which allowed for lazy-loading.
Instead of throwing away this paradigm, what if we just added eager-loading?
REST doesn’t have a query specification or built-in schema, but it does have this Resource concept. Instead of thinking of a bag of fields and types, what if we thought in Resources?:
Resources have Attributes. An Employee has a first_name which is
a string, an age which is an integer, and so forth.
We’d probably want to filter and sort by these attributes right? We might add some additional filters and sorts, we might want to opt-out of others, but querying a Resource by its attributes serves as a reasonable baseline.
If we have an attribute and it’s a string, we know we’re
talking about operators like suffix and prefix, but an integer
attribute would want operators like greater_than and less_than.
Resources also have relationships to other Resources. We should be able to lazy-load those relationships (with Links), or eager-load those relationships. Whether lazy or eager, the same logic should apply.
If we defined these Resources, with their attributes and relationships,
then the input and the output wouldn’t actually matter. Or more
accurately: we can accept and render whatever payload we want. Maybe
we’ll even dynamically serve different payloads based on Content-Type.
OK, so really we don’t need to define inputs and outputs - those can be assumed by convention, swapped on-demand. What we really need to define is the Resource.
Welcome to Graphiti
class EmployeeResource < ApplicationResource
attribute :name, :string, sortable: true, filterable: true
attribute :age, :integer, writable: false
endWith nothing but this Resource definition and some assumed conventions, we get all this behavior out of the box:
- Create
- Update
- Delete
- Read
- Filter
- String (
name)eq(case sensitive)eql(case insensitive)prefixsuffixmatchnot_*(not_eq,not_prefix, etc)
- Dates and Numbers (
age)eqgt(greater than)lt(less than)gte(greater than/equal to)lte(less than/equal to)
- String (
- Sort / Multisort
- Paginate
- Fieldsets
- Filter
Not just an API contract, but out-of-the-📦 behavior. If we know the configuration of a Resource, we can automate query and persistence operations. Obviously we’ll need lots of ways to customize and override, and support for any number of datastores and clients. But if we have the configuration, a defined contract for querying and persisting data, we can build patterns around it.
There’s more to this than a bunch of out-of-the-📦 standards and behavior. If we thought only in Fields and Types, we’d use GraphiQL to see something like:

But if we thought in Resources, it’s not just a big bag of fields. We’re able to organize those fields around meaningful concepts:

This screenshot is from Vandal, the Graphiti UI.
Because we started with a better abstraction, we ended with a more
intuitive
UI. As a marketer-turned-programmer myself, I really
appreciate when data exploration tools like this are friendly to
less-technical users. A user of Vandal doesn’t need to know about Connections
or Edges, they just need to click around. I like that my product owner and I can walk
through the domain together, validating concepts and solidifying a shared
understanding.
HTTP Endpoints
While both GraphQL and Graphiti can fetch your graph of data in a single request, GraphQL does this with a single endpoint. Graphiti keeps RESTful URLs, for three reasons. First, HTTP caching: Phil Sturgeon has an excellent comparison of GraphQL and endpoint-based caching here.
Second, adding endpoints allows for customization. Maybe we want to send
a welcome email when we POST /employees but not when we POST
/admin/employees. Maybe /exemplary_employees applies additional query
logic by default, but wants to re-use everything else. In other words,
Resources form your graph, but Endpoints expose that graph to the
outside world (and hold relevant logic around exposure). Read more in
our Endpoints Guide.
The third reason is lazy-loading with Links, which we’ll cover in a bit.
Schema
We even get schema benefits. Schemas are great for tooling and
backwards-compatibility checks…but when they are oriented around
Fields and Types, they can only tell you so much. When they are oriented
around Resources, they can expose less-obvious concepts. Maybe we sort
Employees by created_at by default:
{
name: "EmployeeResource",
type: "employees",
attributes: { ... },
default_sort: [{ "created_at": "desc" }],
...
}Because this is specified in the schema, not only are clients more informed, but changing this default would raise a backwards-compatibility error:
EmployeeResource: default sort changed from [{:created_at=>"desc"}] to [{:last_name=>"asc"}].When developing in Graphiti, we introspect your Resources and automatically generate the schema for you. Backwards-compatibility checks can be done with a command-line task, or whenever your tests run.
Graphs
You may be thinking, “OK, but REST only works for a single object. I’ll have to make multiple requests, and be right back where I started. I need GraphQL to solve this problem”.
Not true.
Years before GraphQL came out, respected developers from different companies and backgrounds came together and began the discussion on how to improve REST APIs. This wasn’t a project pushed by a hundred-billion dollar company; it was an organic, community-driven effort. The result was the JSON:API standard, which tackled granular queries long ago:
# GET /employees?include=positions
{
data: {
id: "123",
type: "employees",
attributes: { name: "Kayla Webb" },
relationships: {
positions: {
data: { id: "456", type: "positions" }
}
}
},
included: [
{
id: "456",
type: "positions",
attributes: { title: "Engineer" }
}
]
}Wonky payload, right? First of all, don’t be scared. In Graphiti,
you can add .json to the URL and output a more traditional flat
structure:
{
data: {
id: "123",
name: "Jeesoo Ryoo",
positions: [{ id: "456", title: "Engineer" }]
}
}You can absolutely develop in Graphiti this way, but you’d be giving up
some smart things JSON:API does. One example is de-duplicating each node
in the graph: if we’re listing 100 Posts and they all have the same
Author, you’ll have to render that Author 100 times. JSON:API would
only render it once.
Another is the type/id combo:
Namely, those constraints are that all entities must be addressable top level by type and ID. (Very similar to JSON:API in this respect.)
— Tom Dale (@tomdale) October 14, 2016
There’s a bunch of reasons this is important, but one I’ve always been
partial to is websockets. This type/id combo allows us to uniquely
identify records once they’ve been loaded in JS memory. So, every time a
Resource is saved we can push its state (JSON representation) to clients
with a websocket. Here I am randomly updating a bunch of backend data,
and watching the UI update in real-time.

This took only a handful of lines of code, all of which could be packaged into a library to make this automatic.
Another example is lazy-loading data with Links:
A GraphQL response is going to be as slow as the slowest subquery it has to execute to build the response.
— Tom Dale (@tomdale) October 14, 2016
Instead of loading everything up-front, we want to defer loading for
performance reasons. Maybe we want to render our Employee detail page
super quick, and we don’t need to list the Positions until the user
clicks something.
You can do this in GraphQL, but you need to bake logic into the client, which means changing the logic would break clients (read more about this in the Links Guide). Luckily, REST and JSON:API are optimized for lazy-loading:
# ...
positions: {
links: {
related: 'http://example.com/api/positions?filter[employee_id]=123'
}
}
# ...Graphiti generates these Links between Resources automatically. If you change the logic connecting Resources (which applies to eager loading as well), we’ll update the Link - clients can simply follow the link, and we can change logic server-side with no breakage.
There’s a bunch of other great stuff about JSON:API, but that is a topic for another day.
(Quick aside: I’ve always found the name of this project hilariously awkward, easy to confuse with any API outputting JSON. But you could say the same about GraphQL! Just as JSON:API isn’t the only API standard outputting JSON, GraphQL isn’t the only Graph Query Language - in fact, you could call JSON:API a Graph Query Language as well!)
REST != Multiple Requests
Anything you could do with a single Resource, you can do with multiple
Resources. In other words, we can fetch an Employee, and their
Positions - but only active positions where the title starts with
Eng, ordered by created_at. This is called Deep Querying.
The point here is that REST doesn’t mean multiple requests. Sure, our state is now a graph of objects instead of a single object, but there’s no need for a wholesale revamp. In fact, we don’t need to change much at all.

Just as we can query multiple Resources at once, we can also persist multiple objects at once.
When persisting in REST, we send the same object back to the server alongside a verb. That verb tells us if we’re creating, updating (part or whole), or deleting. Same thing here. Let’s specify the verb alongside the relationship:
# ...
positions: {
data: { id: "456", type: "positions", method: "destroy" }
}
# ...There are only 4 possible verbs:
createupdatedestroydisassociate
Oh, and we’ll run everything within a transaction, throwing in conventions for data validation as well:
# Response code 422
{
code: 'unprocessable_entity',
status: '422',
title: "Validation Error",
detail: "Name can't be blank",
source: { pointer: '/data/attributes/name' },
meta: {
attribute: :name,
message: "can't be blank",
code: :blank
}
}Earlier, we covered how REST was optimized for lazy-loading. Graphiti builds on top of REST to add eager-loading, and “eager-persisting”. In other words, we can both read and write a graph of data in a single request.
(Micro) Services
You should think hard before breaking up a Majestic Monolith; beware the tradeoffs. Still, if you need it, Graphiti has your back.
We now have a consistent interface for queries and relationships. We also covered how Resources connect together with Links. Put two and two together, and you’ll see a Resource doesn’t need to be local to same application. We can have cross-API, remote Resources as well.
The popular GraphQL platform Apollo does something similar with Schema Stitching:

You won’t need to write code like this in Graphiti. Because we have conventions, we can automate this stuff. Just supply a URL:
class EmployeeResource < ApplicationResource
has_many :positions, remote: 'http://example.com/api/positions'
endThat’s it. Everything works the same. We can fetch an Employee and her Positions in a single
request, add additional local or remote Resources to the request, and
Deep Query. If you use Vandal, you’ll think it’s all the same API.
Microservices 🎉!
Don't Sleep On This One: Domain-Driven Design

OK, not that DDD. This DDD:
This book can be a little dry, but the concepts are excellent. Let’s check StackOverflow for a quick summary of DDD:
DDD is about trying to make your software a model of a real-world system or process. In using DDD, you are meant to work closely with a domain expert who can explain how the real-world system works. For example, if you’re developing a system that handles the placing of bets on horse races, your domain expert might be an experienced bookmaker.
Between yourself and the domain expert, you build a ubiquitous language (UL), which is basically a conceptual description of the system. The idea is that you should be able to write down what the system does in a way that the domain expert can read it and verify that it is correct. In our betting example, the ubiquitous language would include the definition of words such as ‘race’, ‘bet’, ‘odds’ and so on.
The concepts described by the UL will form the basis of your object-oriented design. DDD provides some clear guidance…recommends several patterns…
- Rob Knight
I trim the quote because the prescriptive patterns of DDD often overshadow its core concepts. The creator of DDD, Eric Evans covered this in his keynote last year.
REST and Resources force a developer to think deeply about their domain, and this leads to better object-oriented code. Rather than a bag of fields and types, Graphiti pushes you to think critically about your domain.
A Resource is what DDD calls an Entity. REST is about moving Domain Entities from client to server and back again.
You don’t need to know anything about DDD to develop in Graphiti. But don’t sleep on it.
Clients
You can use any HTTP client with Graphiti. If you’re using JS, a simple
fetch will do.
But you may be looking for a more robust client, one that takes advantage of Graphiti conventions. Look no further than Spraypaint, our official client heavily inspired by ActiveRecord. Query your API the same way you query your database:
// All of this is chainable
let { data } = await Employee
.where({ name: { prefix: "Jane" } })
.order({ created_at: "desc" })
.page(2).per(10)
.select(['name', 'age'])
.stat({ total: 'count' })
.includes({ positions: 'department' })
.all()
let record = data[0]
record.positions[0].department.name = 'Updated!'
await record.save({ with: { positions: 'department' } })By relying on conventions we can move the URL, request, and response under the hood, allowing you to focus on what matters - your domain.
GraphQL Support
OK, let’s come full circle. Let’s say some of these conventions resonate with you, but nevertheless you’d like to develop a GraphQL API. I still think Graphiti is your best bet, because Graphiti supports GraphQL.
Remember, we started with this long-hand RPC code:
type CreateEmployeeInput {
name: String
age: Int
}
type CreateEmployeePayload {
employee: Employee
}
type UpdateEmployeeInput {
employeeId: ID!
name: String
age: Int
}
type UpdateEmployeePayload {
employee: Employee
}
type DestroyEmployeeInput {
id: ID!
}
type DestroyEmployeePayload {
employee: Employee
}
type Employee {
id: ID!
name: String
}
createEmployee(input: CreateEmployeeInput!): CreateEmployeePayload
updateEmployee(input: UpdateEmployeeInput!): UpdateEmployeePayload
destroyEmployee(input: DestroyEmployeeInput!): DestroyEmployeePayload
employee(id: ID!): EmployeeGraphiti does not need all this boilerplate. But if we have the short-hand, that means we can automatically generate the long-hand. We can introspect the Graphiti Resources, and use graphql-ruby to automatically generate GraphQL code.
That project is graphiti-graphql. While still more of an experiment at this stage, it’s shaping up nicely. The main blockers are the conventions missing from any GraphQL API - how should we render validation errors, which sorting standard should we adopt, etc. But we have proof that if there’s a target to hit, we can autogenerate it.
So we can generate GraphQL via Graphiti, but should we? Maybe! Not an unreasonable pursuit. If you’d like to go down this route, I’d love to hear from you!
Still, let’s be clear what we’re missing: HTTP caching, error codes, lazy-loading, and more.
Magic
Having that level of consistency, and working with that for just a little while means that you can start to forget about it. And that’s the power of conventions in general…it used to be something you had to think about and make a decision. Well, decisions are bad. Decisions take up your brain power, and it requires brain cycles to consider which or the other. The more decisions you can take out of the whole thing, the more brain power you can free up to consider the really important things.
If everybody is doing the same thing in the same way, it means that you can easily go from one application to the other, and expect the same things to happen.
- “Resources on Rails”, David Heinemeier Hansson
When conventions form your programming foundation, you end up with these high-level abstractions where a few lines of code hide the underlying complexity. Often, this is flippantly referred to as ✨”Magic“🔮
The thing about magic is, once you learn the trick it often comes down to something simple: a mirror, a trick deck, a quick hand.
An object, moving back and forth.
Simple concepts can often be the most powerful, and I will never get tired of seeing this trick performed.
There’s plenty more we haven’t even touched on. Check out the Guides, or dive right in with the Quickstart or Tutorial. If things get tricky, ask for help in our Discord Chat. Reach out to me directly at richmolj@gmail.com or @richmolj on Twitter.
Addendum: Holy Shit
I can’t believe I just wrote all that. I swear, I never set out to do any of this.
There are a lot of big ideas here, but this project is not some ideological crusade. Three years ago I had a bug in my application, and I found it surprisingly tricky to fix. I kept pulling that string, I connected with other developers pulling their own strings, one thing led to another, and here we are. This project is nothing more than a good-faith effort to build quality software, based on my own personal experience.
Let’s be clear: GraphQL is awesome. It solves real problems in a user-friendly manner, has sexy tooling and amazing libraries created by kickass developers. There are many advantages of GraphQL not covered here, and plenty more great ideas I’d like to steal. If you find some of the framing here annoying, if you find yourself thinking “…but what about X and Y?”, just know I feel the same way whenever a GraphQL post talks about REST. It will be a continual goal of this project to raise the level of debate.
Same for RPC. I work for a company that made billions off of RPC. I tend to think REST is a better fit for the web, and RPC is a better fit for things like financial trading systems or video games, but plenty of reasonable people can disagree. Conventions and abstractions come with their own cost: a learning curve, indirection, lack of flexibility. If you prefer something more low-level, I completely understand. I’ll continue trying to learn from you.
Beware projects and ideologies that claim to be a solution to all your problems. Everything has tradeoffs. The best we can do is to avoid zero-sum thinking, and instead think about how we can take the best ideas from a variety of solutions and experiences, striving to continually improve. It is hard, it is exhausting, it is the right thing to do.
Unless you like XML. Screw XML.
